 I am a twenty-four year-old software security engineer. In the past I've worked on
I am a twenty-four year-old software security engineer. In the past I've worked on I often use Safari’s Reader function when I come across articles that have tiny print, are contrained along a very narrow column, or are broken up by enormous ads. For those of you unfamiliar with Safari’s Reader, it basically performs the same function as the Readable bookmarklet: it extracts the body of an article and presents it in an easy-to-read format. Here’s an example:
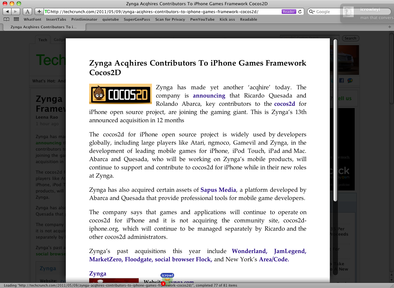
The problem is, of course, what determines how the article is extracted? And, in that case, how the title is extracted? I ran into this problem when designing my blog, resulting in the title of every article appearing as “[between extremes]” – my blog title, not the article title – in the Reader.

Weird. I searched a bit for “Safari Reader documentation” and found nothing, so I futzed around with the HTML and eventually got it to work by adding the “title” class to the <h3> tag holding the title. Problem solved, pack it up and move on.
Hang on a second, though. I started to wonder what algorithm Safari uses for extracting articles. Then I realized the easiest way to write something like Safari Reader would be in plain JS, with the HTML already parsed into a DOM and whatnot. So I decided to see if Safari injects the code for Reader into the page, for the sole sake of science. A minute later I found the code and came to the conclusion that Safari Reader is just a glorified Safari extension, consisting of an injected script, style, and toolbar button.
For legal reasons I don’t think I can just post the code, but here’s how to access it:
- Open Hacker News in Safari (no sense in wasting a tab)
- Open Web Inspector (cmd-option-I)
- Open the Scripts tab, click Enable Debugging
- Pause the Javascript interpreter (above "Watch Expressions")
- Refresh the page
- Step through the code line-by-line. Eventually you'll get to the Safari Reader code
The JS code that you now see in the Web Inspector is the article extraction algorithm for Safari Reader. Incredibly, the code is not packed or minified, so by throwing it through jsbeautifier, you can end up with some nice, readable code. A couple of interesting things I noticed by glancing through the code:
- The script uses a Levenshtein distance calculation sometimes to check if a certain string of text agrees enough with the article to be the title.
- ~1200 lines of Javascript, hundreds of arrays, and not a single splice() call
- The algorithm works by slowly trimming irrelevant DOM nodes, ending up with just the article content
- For a certain body of text to be the primary article candidate, it must have at least 10 commas
- The "#disqus_thread" identifier is one of the few, hardcoded, values the parser automatically skips
- The algorithm also parses next page URL by looking for the link with the best "score"
- You can copy and paste this script into the console of any browser. To run it, you would type:
var ReaderArticleFinderJS = new ReaderArticleFinder(document);
var article = ReaderArticleFinderJS.findArticle();This code might be valuable to anyone looking to scrape text content from HTML. If anyone has better pointers into the script’s inner workings, feel free to comment!
 Github
Github